No matter how much we love technology, it is always a means to an end. The mission comes first – we don’t do tech for its own sake, we use tech to get the mission done.
What we really care about is building badass engineers who love their work, who love collaborating, who have tools that help them succeed and get out of the way. We love creating the circumstances necessary for powerful teams to emerge.
Engineers are humans too (99.96% likelihood)
We hold the somewhat controversial opinion that engineers are people too. (Hang on … hear us out.)
We’re never going to brag that we have some magical anomaly detection or machine-generated automated root cause analysis, because that would be stupid (thanks Allspaw!)
We are telling you we can empower your humans and make them better at engineering, and make your teams stronger too. We are big believers in Kathy Sierra’s approach to building Badass Users by building tools that quite literally increase User Badassity the longer they are used.
This isn’t just a theory, we’ve seen it play out repeatedly. Developer tools have a sordid history of building tools for ourselves like we aren’t prone to the same biases and nudges as everyone else. Building for utility and building for delight are not opposing objectives.
We are also building ways to capture and curate an institutional “brain” for your team … because people forget things, people leave, people get distracted. Honeycomb always helps you follow not only what the answer is but how you or your team members arrived there
At Honeycomb we have very intentionally chosen against creating yet another query language, or making you type in lengthy dotted metrics. These might be shortcuts to building a power tool, but they are fierce obstacles to natural learning. Our user experience places playfulness and exploration front and center.
| Old Way |
New Way |
| Developer tools have historically been ugly, offputting things that you were forced to use because there was no other option. ❌ |
We want to build tools that you become hooked on, that feel like a part of you, because you are so much more powerful when you use them. We want them to be as intuitive and usable and delightful as any consumer product. |
For example: Every team I’ve ever been on has had metric nerds, a couple of people who really love geeking out over graphs. (The rest of us are normal human beings.)
You’ll see them up late at night peering over graphs and constructing elaborate views. I’ve never been one of those people … but I’ve always appreciated that working with them made me better. I would carefully bookmark and save some of the work that they did, and it made me better at my own work.
At Honeycomb, we’ve baked this into the product. Sharing, reusing, iterating, bookmarking, and so forth are all first class features. I’m so excited about building tools that won’t fight me on this and make it harder, but will actually make it easier for those awesome metrics nerds to expand their reach and increase their impact.
| Old Way |
New Way |
| Everybody had to learn to debug every single thing from scratch, for themselves, even if they are the 20th person on the team to do so, even if it’s 4 am and the service is down. ❌ |
Leverage the work of each other so your time is spent on the highest-impact work. Empower the metrics nerds to have wider impact by creating all those views and attributes you can all reuse and learn from. |
- Lets you gracefully hand off from one on-call shift to the other, so your buddy can go back and see how you debugged critical problems from beginning to end
- Creates a production runbook just by using it that you can use to see what everyone else on your team is trying to understand and debug
- Lets you capture and trace every appearance of a unique request ID as it traverses the stack, hits various service and data stores, and returns to the user
- Creates a shared reality for everyone – from C-level to mobile engineers, to backend software engineers or SREs, even marketing, sales and technical support
- Helps you onboard and train new hires and junior engineers … at their own speed, as needed
- Lets your senior engineers actually go on vacation by capturing their thought process around critical processes
- Posts a complete debugging run back to a Jira ticket or Asana task once you finish debugging … so the person who filed it can debug it themselves next time.
- Helps distributed teams collaborate effectivaly, by posting results and comments to Slack channels, where other people can click to iterate off any point in the run.
We want to make it easy to get up and going, to integrate with any tools you already love and gradually replace the ones you use and don’t love, by piggybacking on the work you’ve already done. Our API just takes JSON blobs, from any source whatsoever. We value your time, so you should have to redo as little work as possible.
| Old Way |
New Way |
| Build everything custom and in-house. Spend your precious engineering cycles building the same solutions over and over again at every job, from email to log aggregation to monitoring and alerting and metrics, hell why not write your own storage and filesystems while you’re at it? Good lord.. ❌ |
Engineering talent is rare; don’t waste it on anything that’s not core to your business, that isn’t a key differentiator. Spend your core cycles on your own products, and let experts in the field do everything that isn’t the critical path. I guarantee they can do it more cost-effectively and better than you can. |
In summary …
The key to becoming a better engineer is to get your hands dirty. Don’t be terrified to break things. Know how to break them controlledly, in small chunks, in reversable ways.
Build guard rails, not fences.
Get used to interacting with your observability tooling every day. As part of your release cycle, or just out of curiosity. Honestly, things are broken all the time — you don’t even know what normal looks like unless you’re also interacting with your observability tooling under “normal” circumstances.
The best engineers I’ve ever worked with are people who spent nearly as much time in their tooling and their observability as their IDE or their code. I’d be cool with a slogan like “code less, think more.”
Consider the children.
It has never been harder than it is now to recruit, hire and retain top engineering talent. Why do companies insist on whiling away those skills, on engineering problems that have nothing to do with their core differentiators?
Honeycomb is about the future: a version of the future where most people have woken up to this reality, and have stopped trying to waste scarce engineering cycles on their own observability tooling, just like most companies no longer run their own email and spam filters.
Let us help you build better engineers, and take challenging problems off your hands so you can focus on your key work.
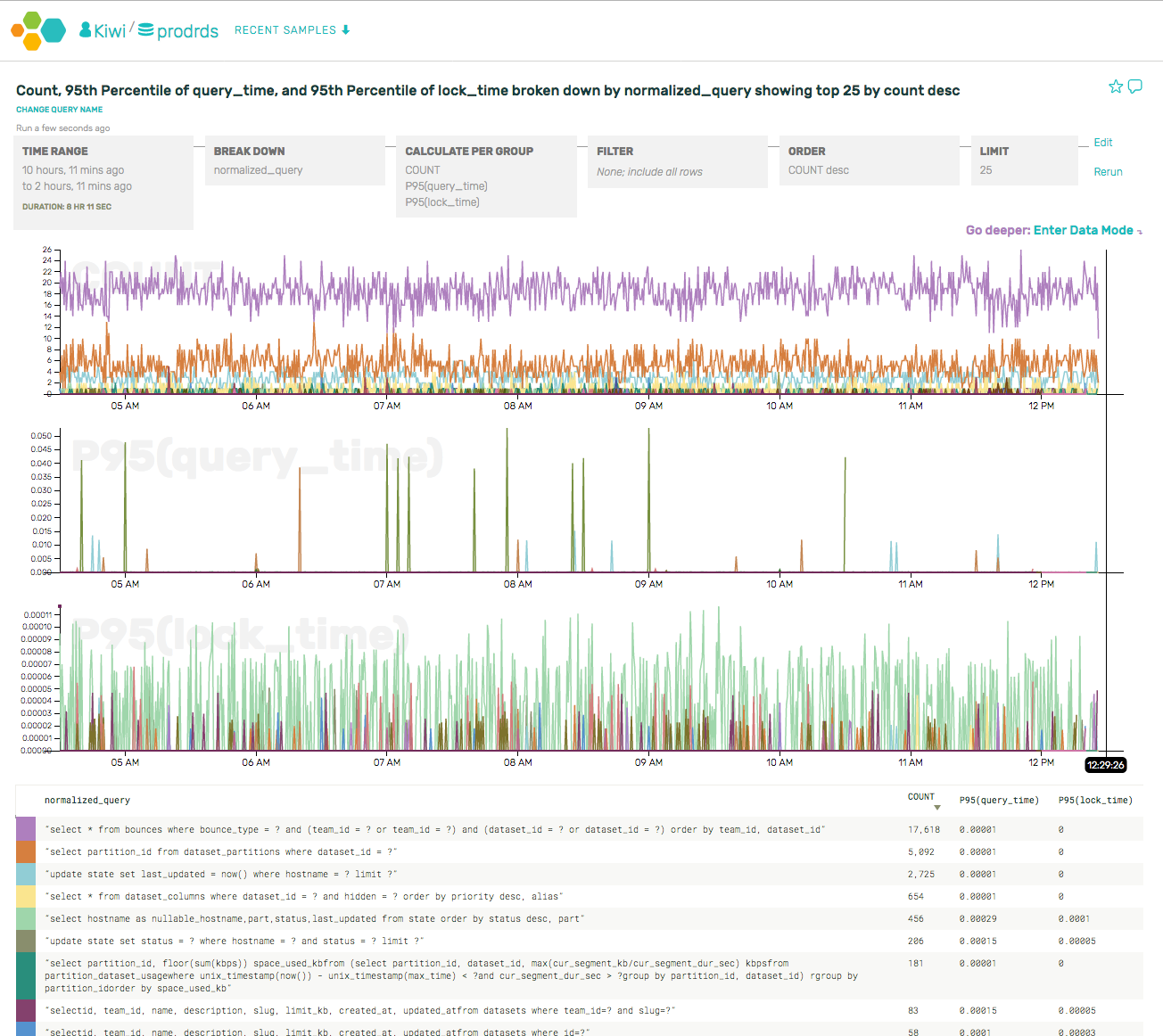
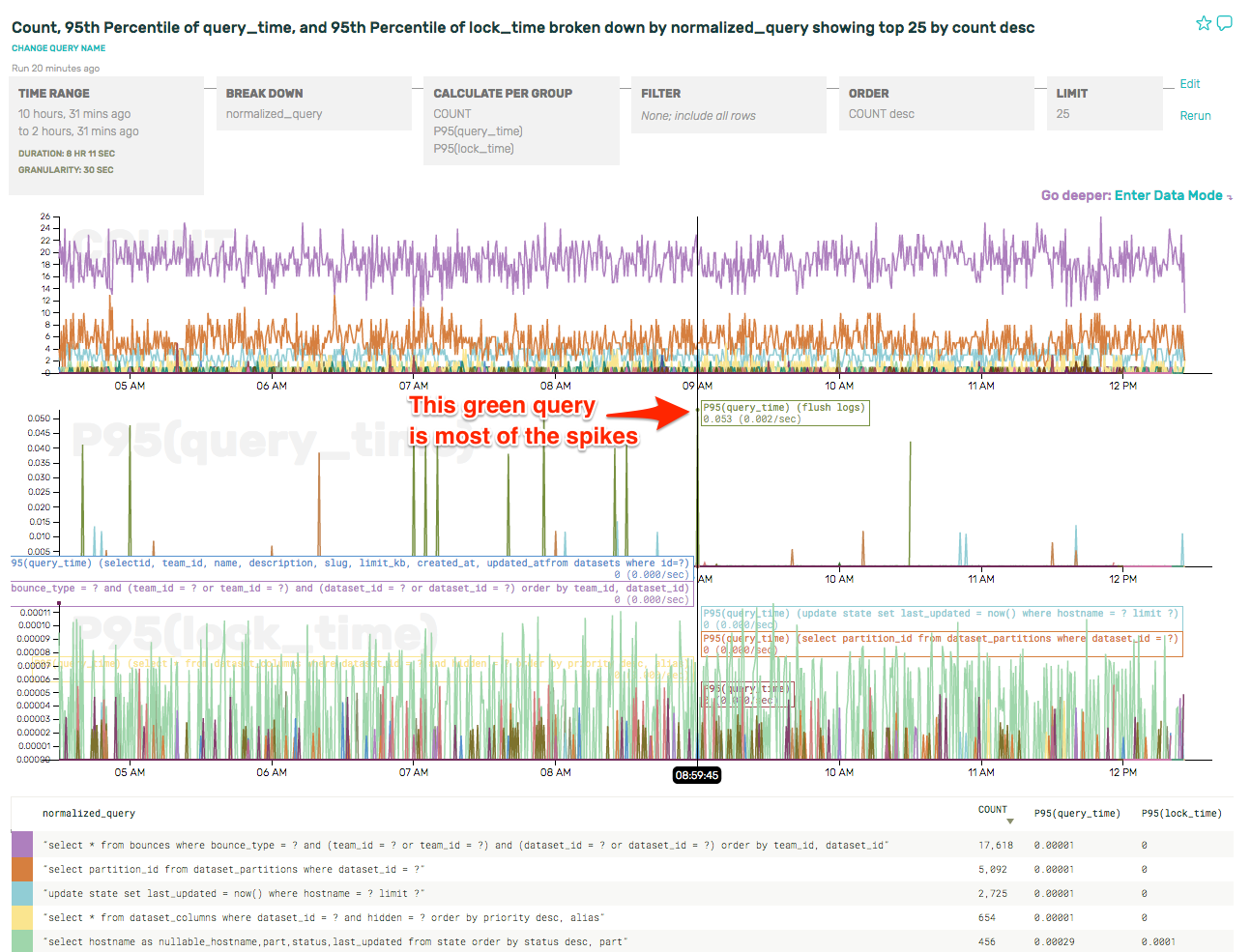
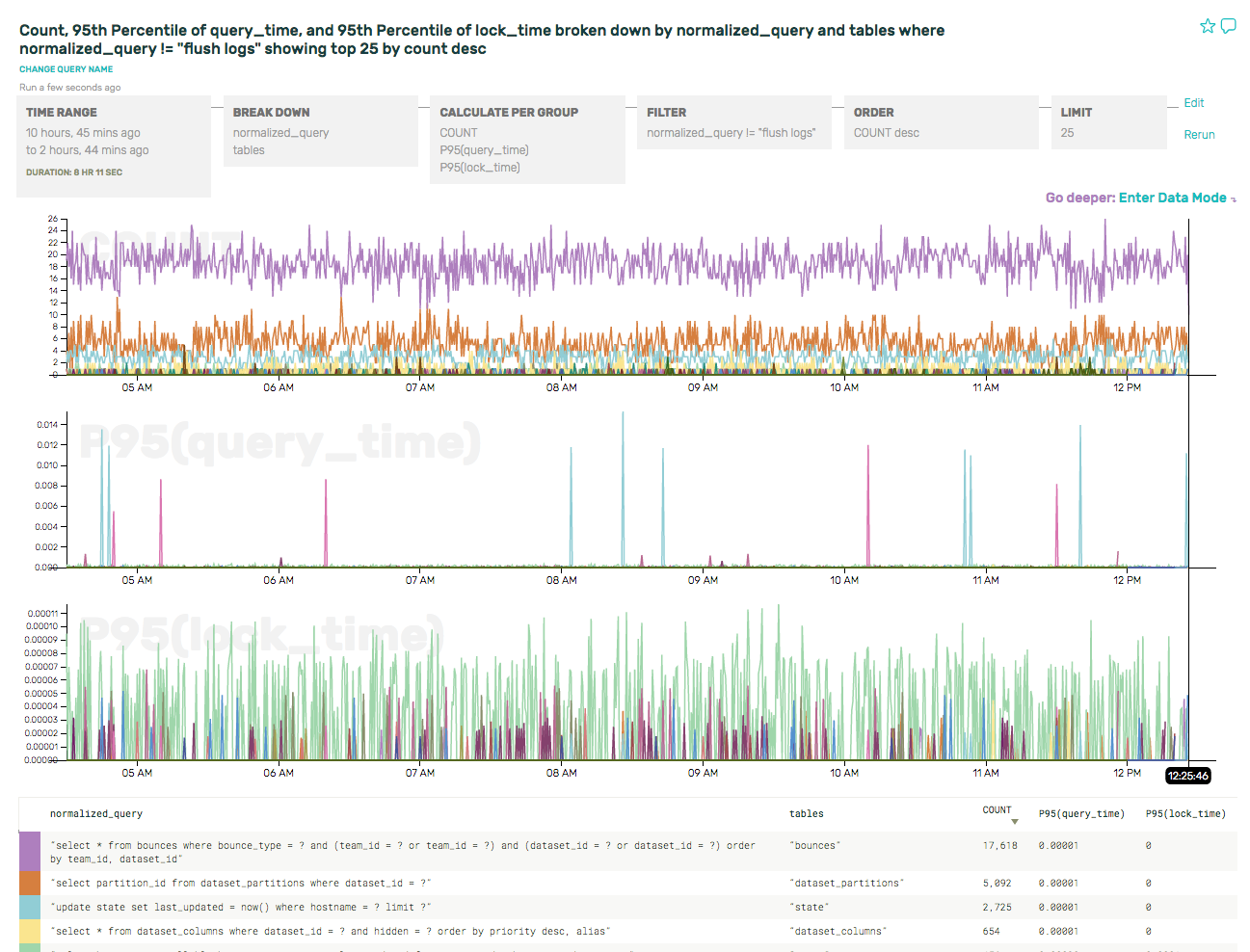
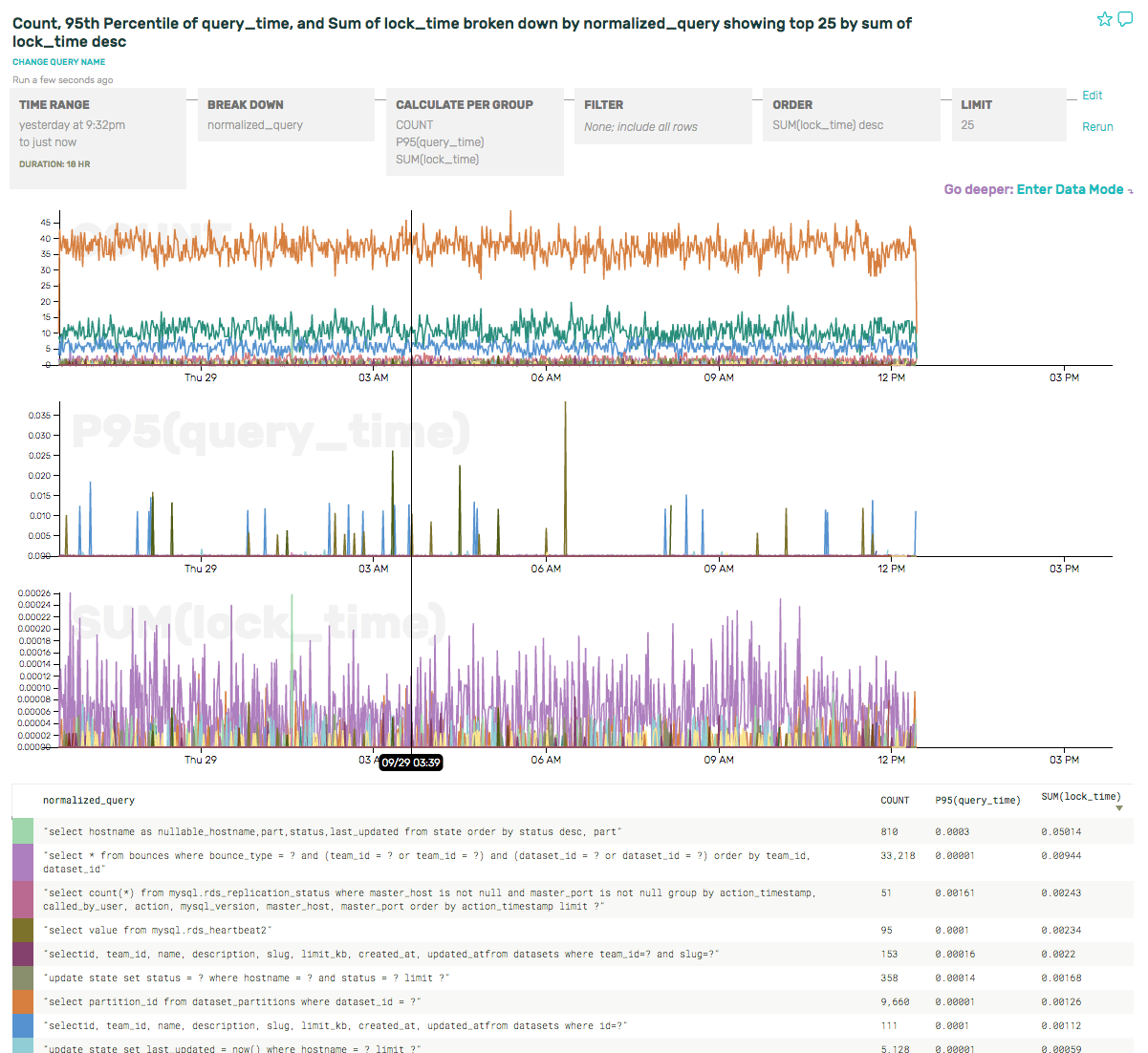
 (As an aside, we also got to file a bug against ourselves for using
(As an aside, we also got to file a bug against ourselves for using