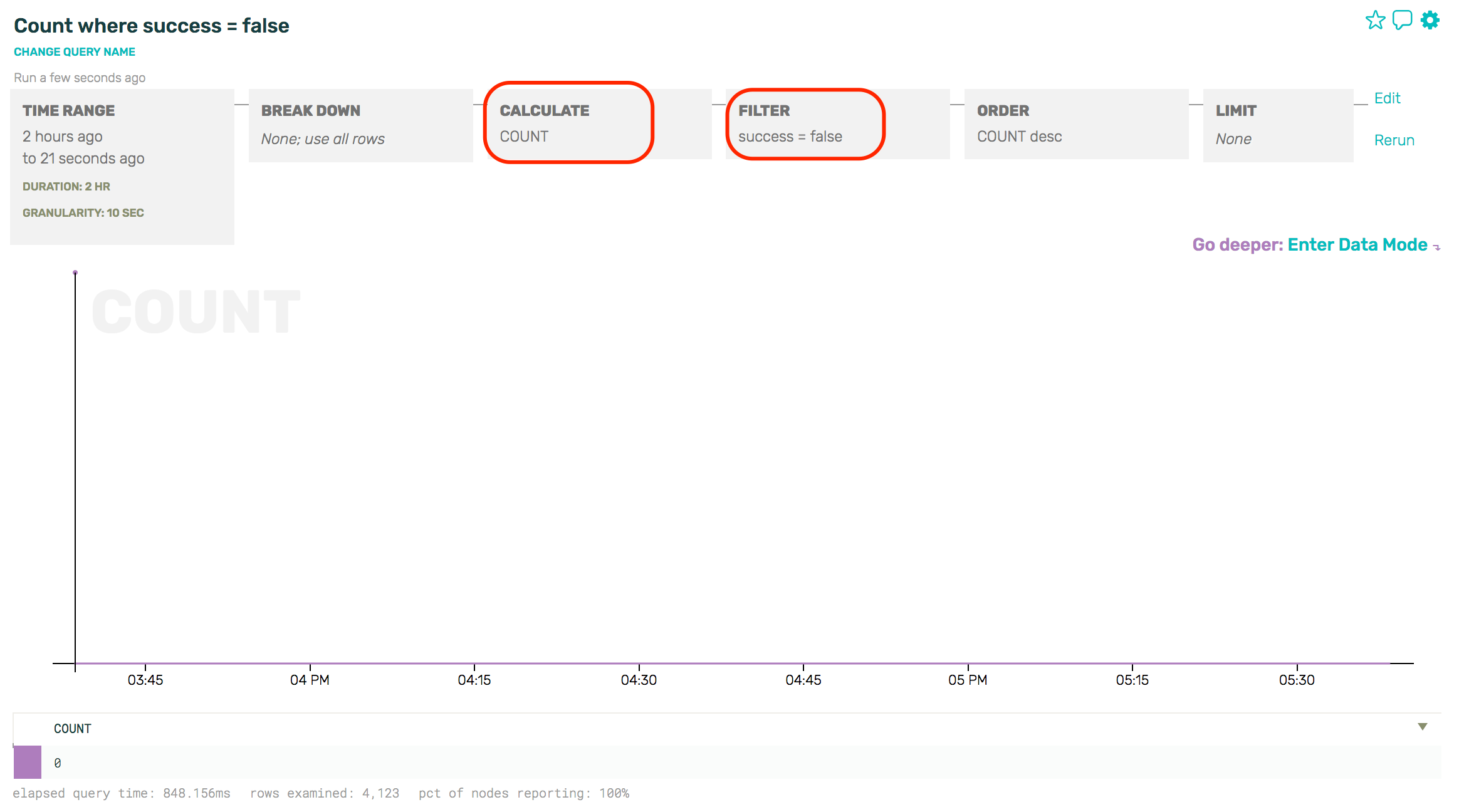
This is the third in a series of guest posts about instrumentation. Like it? Check out the other posts in this series. Ping Julia or Charity with feedback!
There is a way to structure programs that makes inclusion of instrumentation straightforward and automatic, and it’s one that every hardware and software engineer should be completely familiar with: finite state machines. You have seen them time and again as illustration of how a system works:
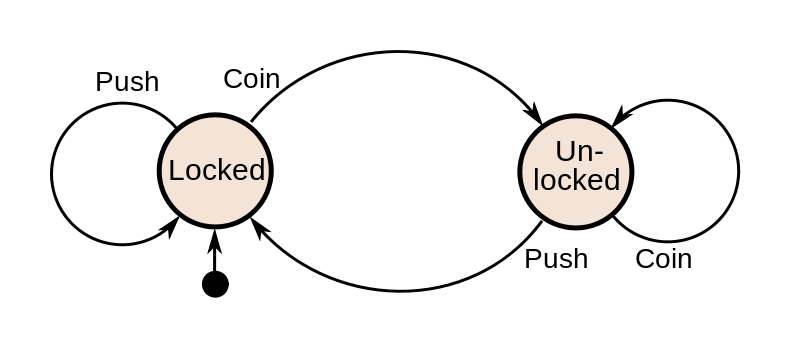
What makes FSM instrumentation straightforward is that the place to expose information is obvious: along the edges, when the state of the system is changing. What makes it automatic is that some generic actor is usually driving a host of specific FSMs. You only need to instrument the actor (“entering state Q with message P”, “leaving state S with result R”), and every FSM it runs will be instrumented for free.
I learned how easy FSMs are to instrument while working on Webmachine, the webserver that is known for implementing the “HTTP Flowchart”. (click for the full flowchart)
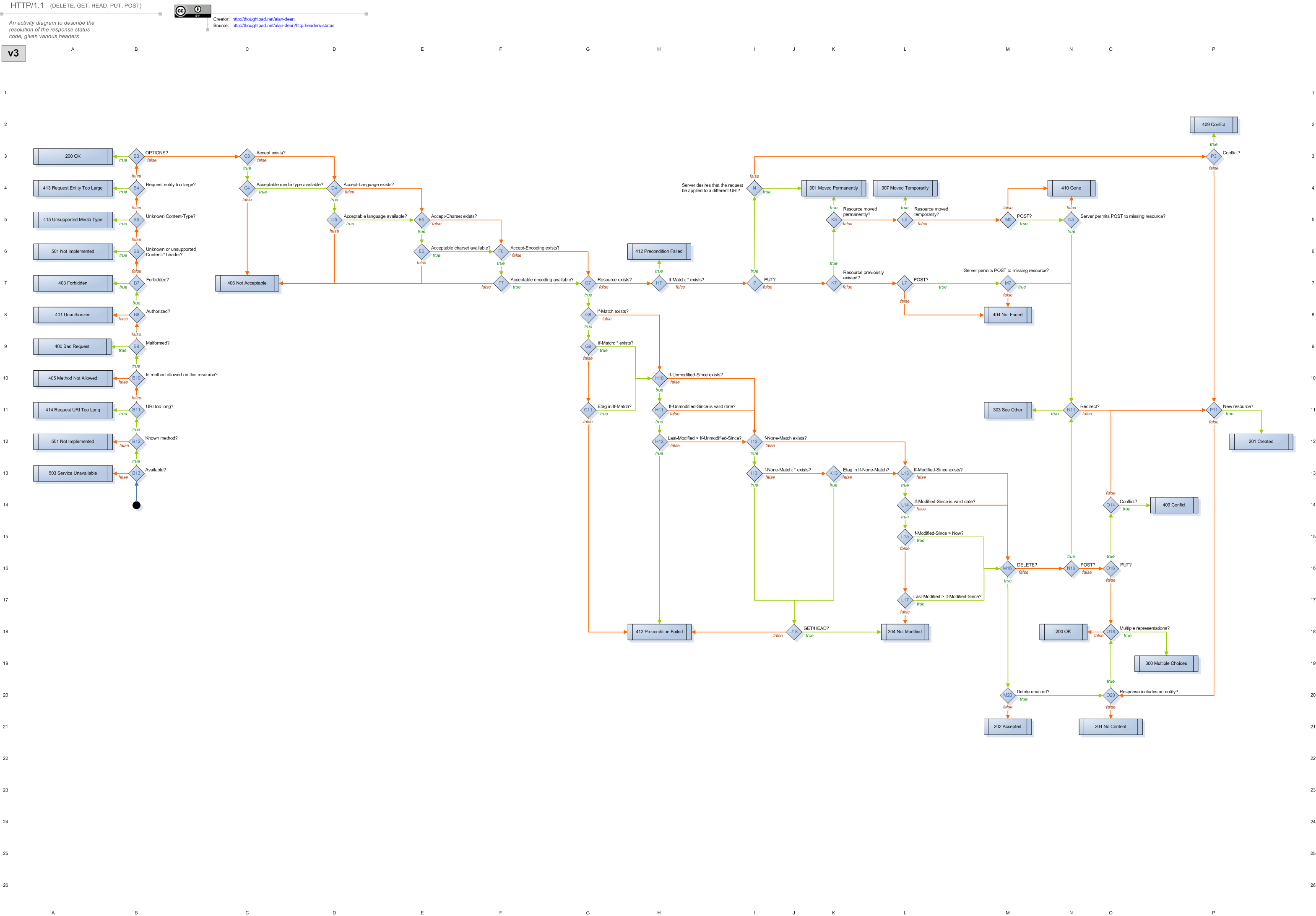
Each Webmachine resource (a module handling a request) is composed of a set of decision functions. The functions are named for the points in the flowchart where decisions have to be made about which branch to follow. This is just alternate terminology, though: the flowchart and resource describe an FSM, in which the decision points (and terminals) are states.
Driving the execution of a Webmachine resource is a module called webmachine_decision_core. This is where the logic lives for which function to call, and which branch to take based on the result. It triggers each function evaluation by calling a generic webmachine_resource:resource_call function, with the name of the decision.
resource_call(F, ReqData,
#wm_resource{
module=R_Mod,
modstate=R_ModState,
trace=R_Trace
}) ->
case R_Trace of
false -> nop;
_ -> log_call(R_Trace, attempt, R_Mod, F, [ReqData, R_ModState])
end,
Result = try
apply(R_Mod, F, [ReqData, R_ModState])
catch C:R ->
Reason = {C, R, trim_trace(erlang:get_stacktrace())},
{{error, Reason}, ReqData, R_ModState}
end,
case R_Trace of
false -> nop;
_ -> log_call(R_Trace, result, R_Mod, F, Result)
end,
Result.
This is where the ease of instrumenting an FSM is obvious. The entirety of the hooks needed to support tracing and visual debugging of every Webmachine resource are those two log_call lines. They record the entrance and exit of each state of the FSM without requiring any code to complicate the implementation of the resource module itself. For example, a simple resource:
-module(blogapp_resource).
-export([
init/1,
content_types_provided/2,
to_html/2
]).
-include_lib("webmachine/include/webmachine.hrl").
init([]) ->
{{trace, "/tmp"}, undefined}.
content_types_provided(ReqData, State) ->
{[{"text/html", to_html}], ReqData, State}.
to_html(ReqData, State) ->
{"<html><body>Hello, new world</body></html>", ReqData, State}.
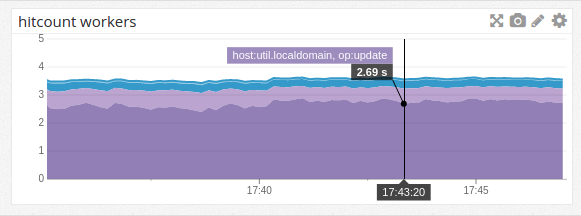
This resource does no logging of its own (as you can see), but for each request it receives, a file is created in /tmp that can be rendered with the Webmachine visual debugger. For example, the processing for a request that specifies Accept: text/html looks like this (live example):
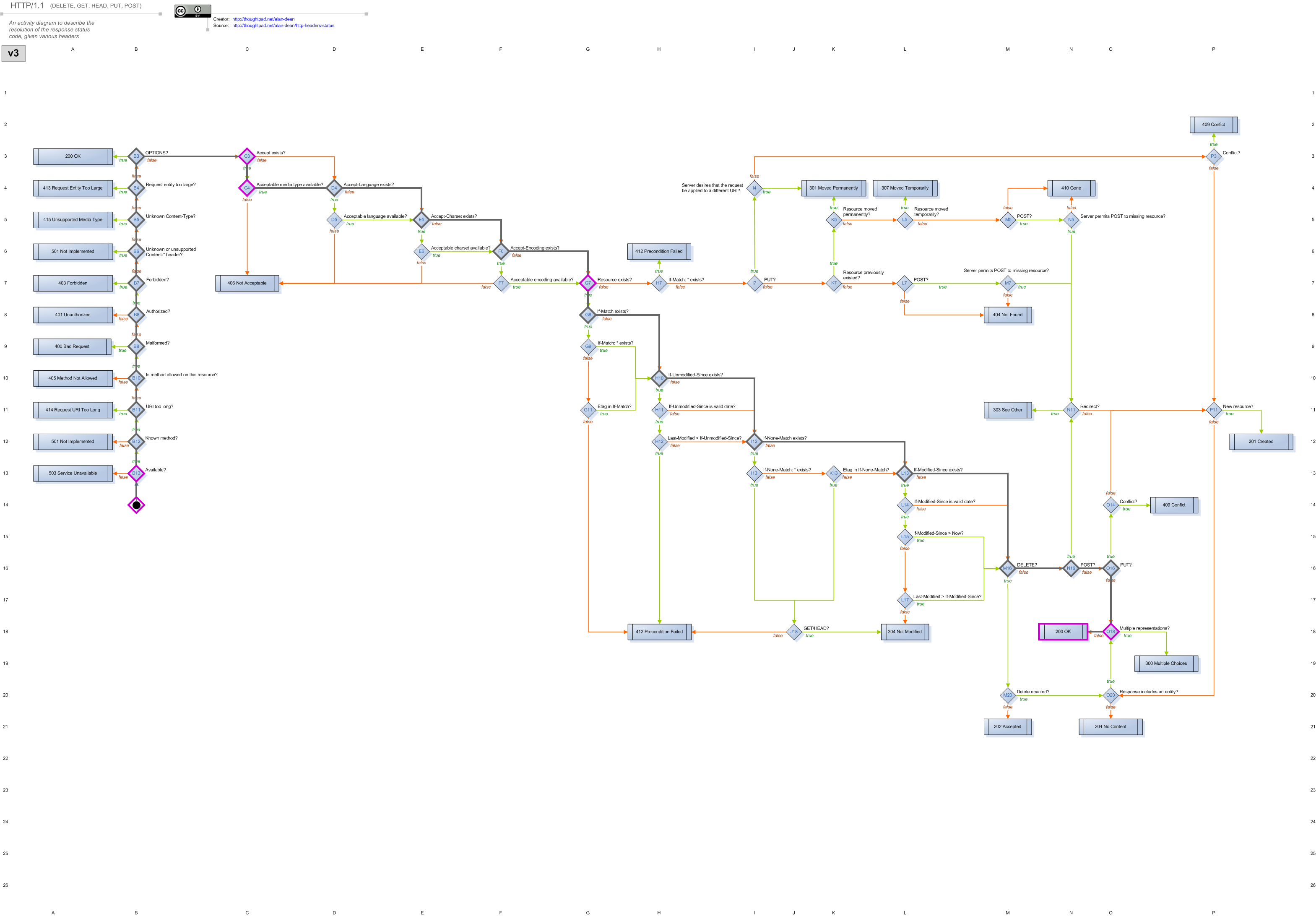
It’s easy to see that the request made it all the way to the 200 OK result at grid location N18. Along the way, it passed through many decisions where the default behavior was chosen (grey-outlined diamonds), and a few where the resource’s own implementation was called (purple-outlined diamonds). Clicking on any decision will display more information about what happened there.
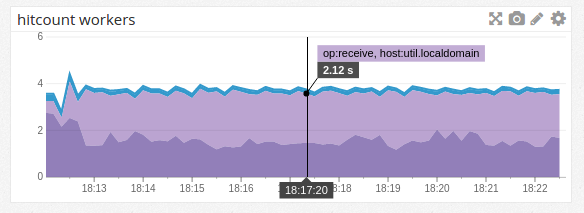
In contrast, the processing for a request that specifies Accept: application/json looks like this (live example):
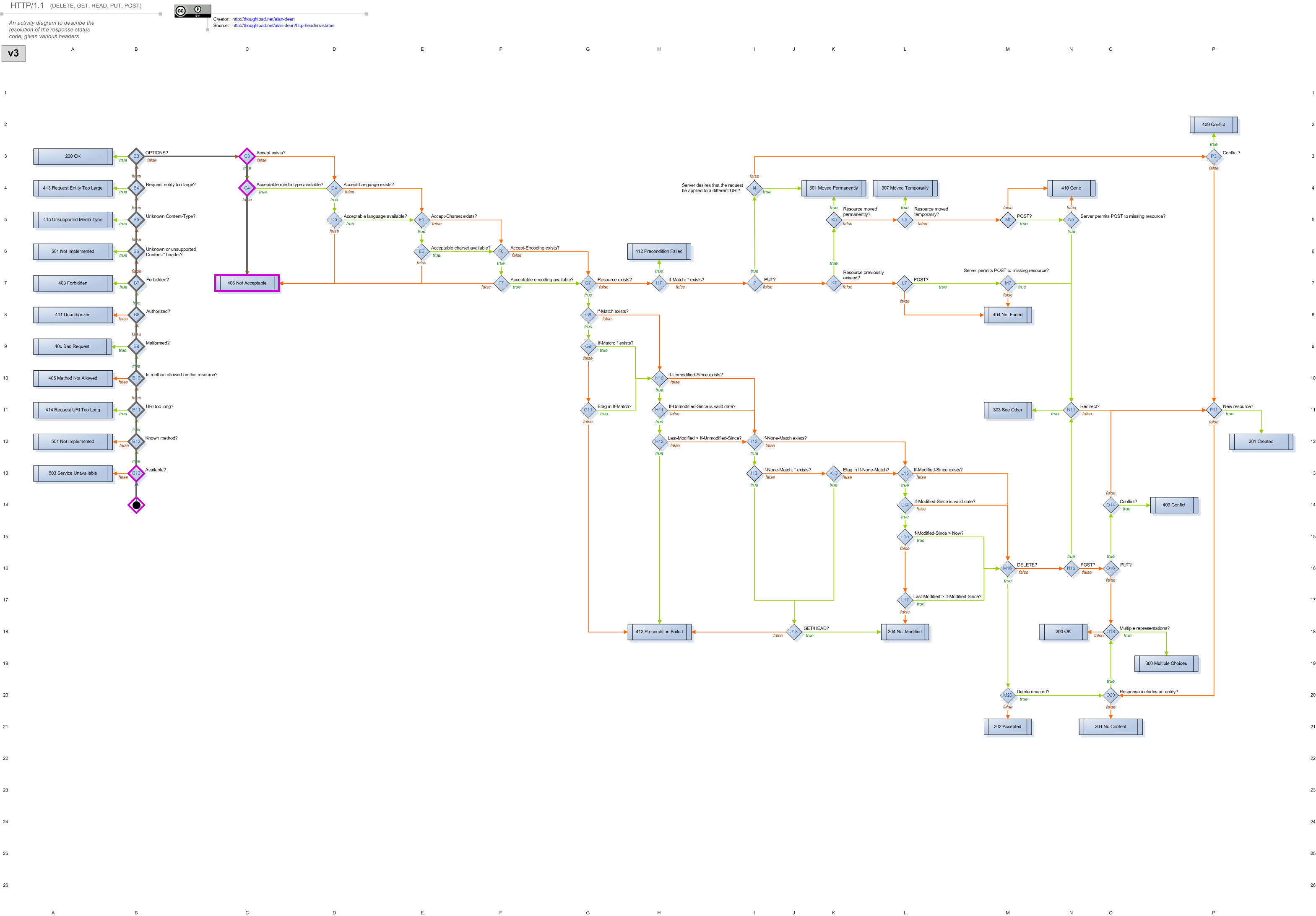
Now it’s easy to see that the request stopped at the 406 Not Acceptable result at grid location C7 instead. For no more code than specifying where to put the log output, we’ve gotten the complete story of how each request was handled. In case you prefer the original text to this visual styling, I’ve also archived the raw trace files.
This sort of regular, simple instrumentation may seem naive, but the regularity and simplicity offer some benefits. For example, all of the instrumentation points have obvious names: they are the same as the states of the FSM. This alone continues to help beginners bootstrap their understanding of Webmachine. When they’re confused about why something happened, they can go straight to the trace or debugger, and either search for the name of the decision they expected to turn differently, or find the name of the decision that did go differently, and know exactly where to return to in their code. Resource implementors add no code, but get well-labeled tracing for free.
Finite state machines can be found under many other names: flowcharts, chains, pipelines, decision trees, and more. Any staged-processing workflow benefits from a basic “stage X began work W”, “stage X finished work W”, which is completely independent of what the stage is doing, and is equivalent to the stage entering and exiting the “working” state. See Hadoop’s job statistics for an example: generically generated start/stop information that an operator can use to get a basic idea of progress without needing the job implementor to add their own instrumentation. I sometimes even consider the basic request/response logging of multi-service systems as a form of this: sending a request is equivalent to entering a waiting state, etc.
To speak more broadly, the important points to instrument are those when application state is changing. This is how I track down where a process diverged from its expected path, or how long it took to make the change. Finite state machines help by making those points more obvious. Instrumenting state transitions reduces the burden on the implementor, by naturally answering the question of where instrumentation belongs and what it’s called. It also reduces the burden on the user of learning what the implementor decided. Inspection of the system becomes easier because the state transitions are always instrumented, and instrumented in a way that maps directly to the system’s operation.
Thanks again to Bryan Fink for their contribution to this instrumentation series!