This is the second post in our second week on instrumentation. Want more? Check out the other posts in this series. Ping Julia or Charity with feedback!
Everybody talks about uptime, and any SLA you have probably guarantees some degree of availability. But what does it really mean, and how do you measure it?
- If your service returns
200/OK does that mean it’s up?
- If your request takes over 10s to return a
200/OK, is it up?
- If your service works for customer A but not customer B, is it up?
- If customer C didn’t try to reach your service while it was down, was it really down?
- If the service degraded gracefully, was it down? If the service was read-only, was it down?
- If you accept and acknowledge a request but drop it, are you really up? What if it retries and succeeds the second time? What if it increments the same counter twice? Is it up if it takes 5 tries but nobody notices because it was in the background? Is it up if the user got a timeout and believed it failed, but in fact the db write succeeded in the background??
We can argue about this all day and all night (buy us a whiskey and we definitely will), but it boils down to this: if your users are happy and think it’s up, it’s up; if your users are unhappy and think it’s down, it’s down. Now we just have to approximate this with measurable things. Here are some places to start.
Start from the top
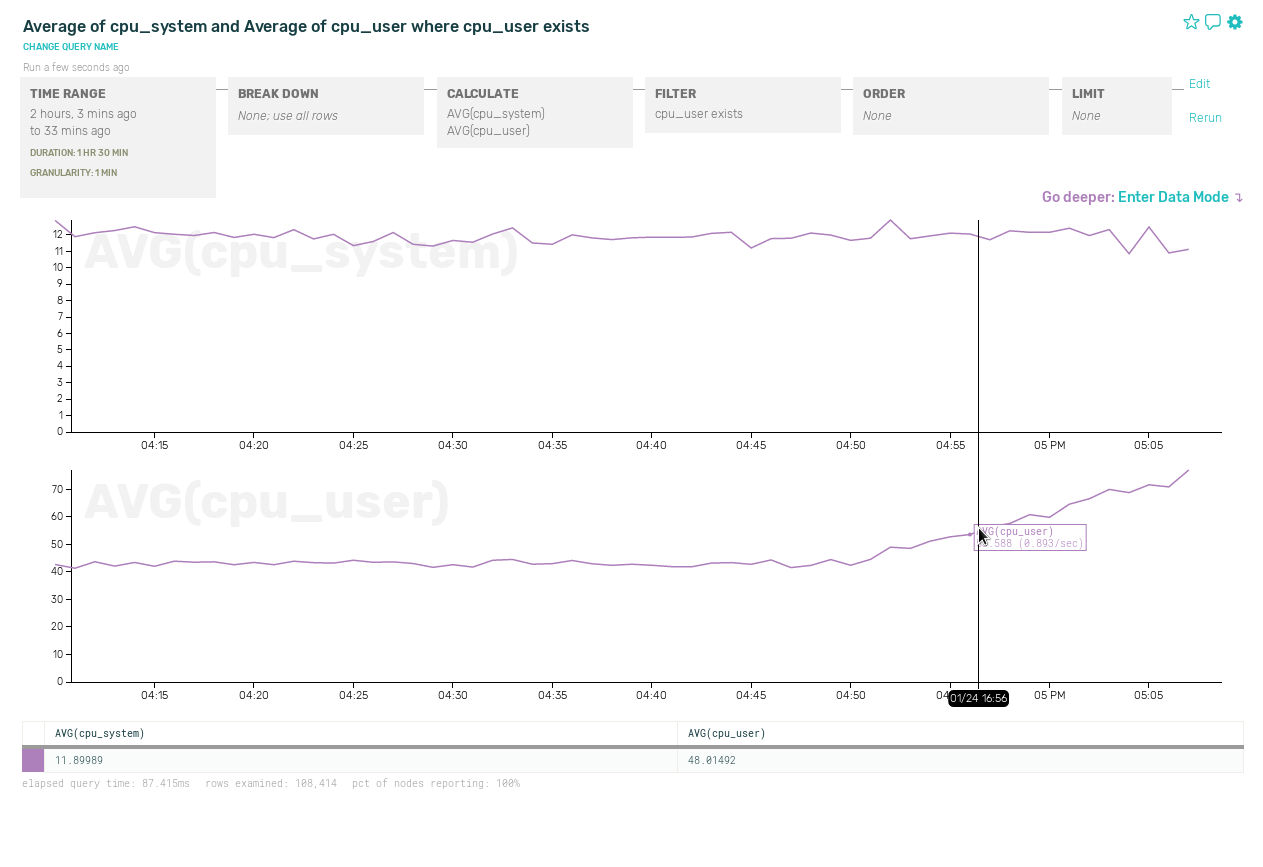
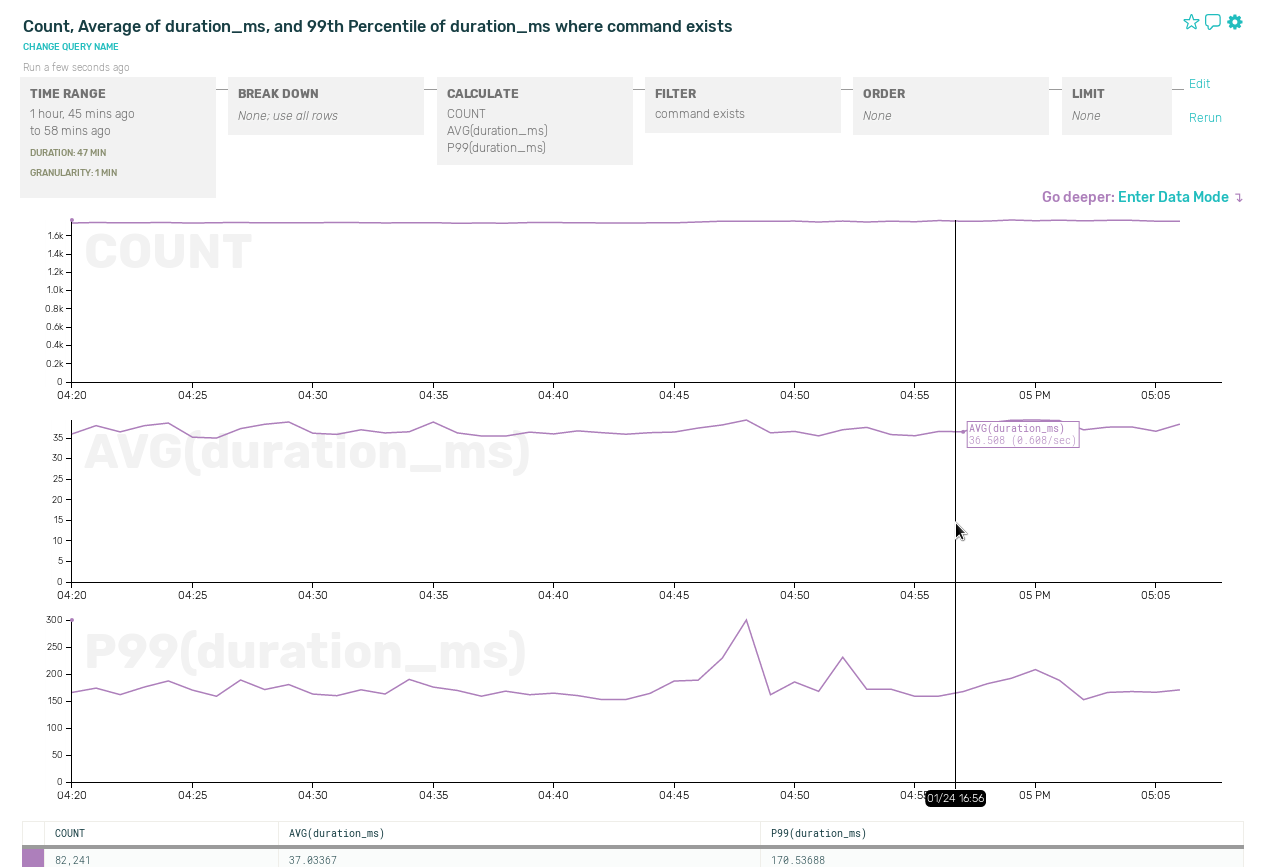
First, start at the top of your stack (usually a load balancer) and track all requests plus their status code and duration. Successful requests under your promised response time is your first approximation of uptime. Failures here will usually detract from your overall uptime, and successes will usually but not always contribute to your success rate.
“But wait!”, you might be saying. “What is a successful request? Is a 200, any 20, any 20 and 30*? What if there are a bunch of 404s but they’re working as intended? How long is too long? What if I served every request perfectly, but a quarter of users couldn’t reach the site due to Comcast’s shitty router tables? Gaahhh!”
This is where Service Level Agreements (SLA)’s come in. Every word needs to be defined in a way that you and your users agree upon. Which is why you should monitor independently and understand how they’re gathering their numbers. (“No, Frank, I don’t think running nmap from your Comcast At Home line is a great way to determine if I owe you a refund this month.”)
Users complicate everything
Do you have any data sharded by userid? Cool, then your life gets even more interesting! You need to map out the path that each user can take and monitor it separately. Because now you have at least two different availability numbers – the global uptime, and the uptime for each slice of users.
It’s important to separate these, because your engineering team likely measures their progress by the first while your SLA may use the second. If one customer is on a shard that has a 100% downtime for an hour, you don’t want to have to pay out for breaking the SLA for the 100k other customers who weren’t affected.
SLAs are their own particular dark art. Get a Google engineer drunk someday and ask them questions about SLAs. Secretly time them and track their TTT (Time Til Tears).
Ugh, features
And then there’s entry points, and features. Consider all the different entry points you have for specific features. If there’s a different read and write path, you must instrument both. If there are features used by some customers (push notifications, scheduled jobs, lookup services, etc.) that have different entry points to your service, you must weight them and add them to the global uptime metric as well as the SLA for each user.
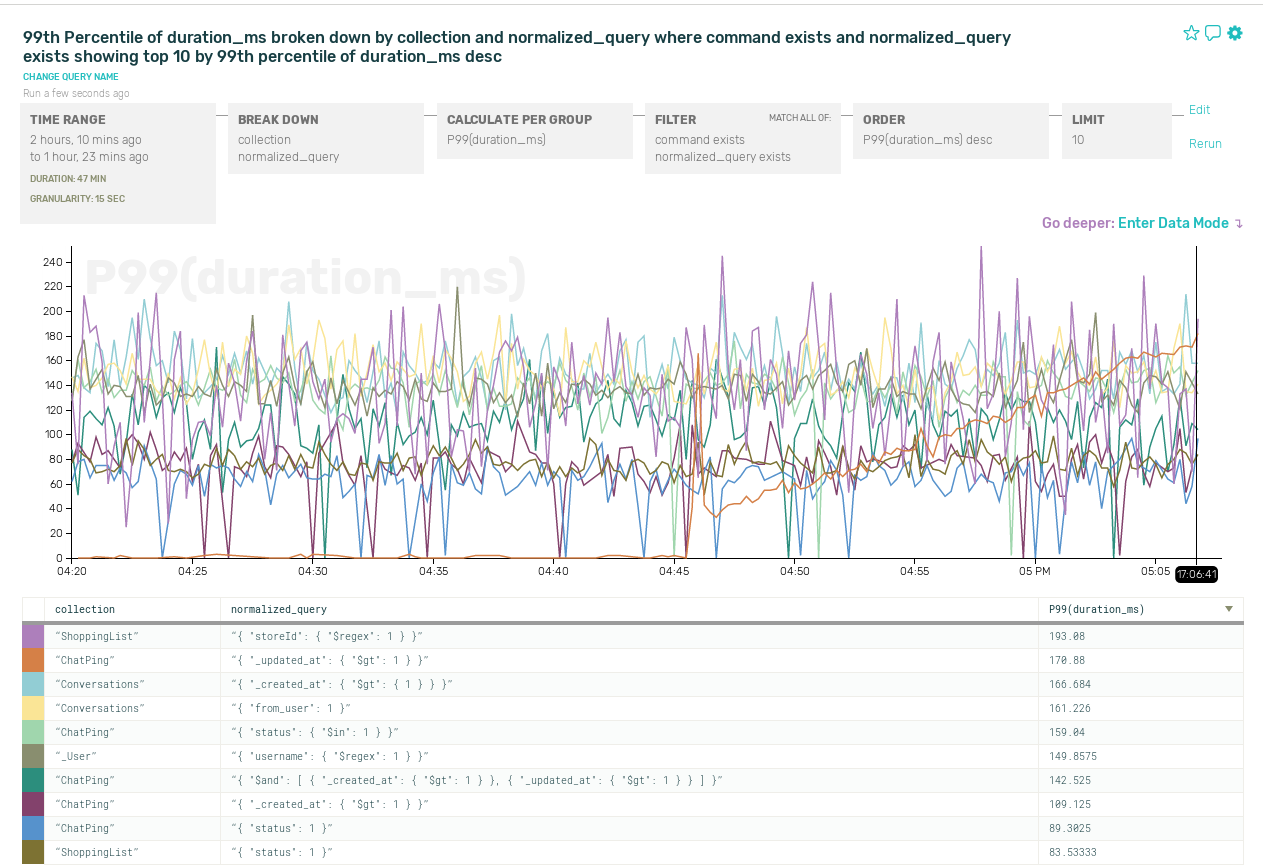
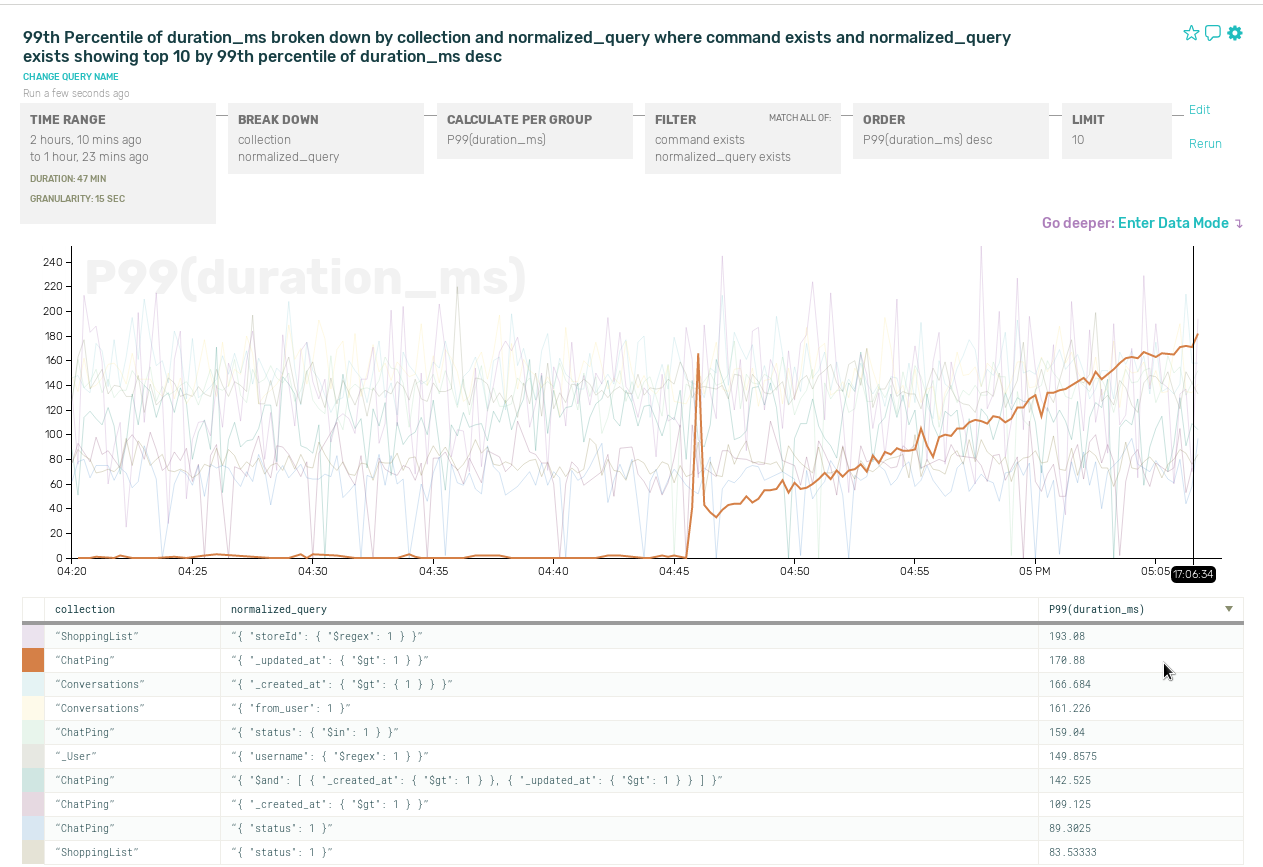
Measuring failures at each individual point within your service can miss connections between components, which is why end to end checks are the gold standard.
And finally, there’s failures outside your control. For example, if your DNS is misconfigured, your customers will never even arrive at your service in order for you to measure their failure rate. If you are using a cloud load balancer service, some errors will not land in your logs for you to measure. For these types of errors, you need to take your measurements from outside the boundaries of your service.
AWS ate my packets
Your users don’t really care if it’s your fault or your service provider’s fault. It’s still your responsibility. Don’t blog and point fingers, that’s tacky. Build for resilience as much as you can, be honest about where you can’t or don’t want to.
Should you feel responsible? Well, you chose the vendor, didn’t you?
Now you have a whole bunch of numbers. But your users don’t want that either. They just want to know if you were up 99.9% of the time. The more data you give them the more confused they get. Doesn’t anything work? Is Life itself a Lie??
Pause, reconsider your life choices
Want a shortcut? Do these two things:
- Set up an end to end check for each major path and shard in your service. Use that as your primary uptime measurement.
- Send events from each subservice application server to a service that can give you per-customer success rates and use that as your secondary source.
Between those two, you will cover 3 nines’ worth of your uptime requirements.
Having something now is better than agonizing over this for long. While your team is busy arguing vigorously about how good your uptime check is, do something simple and start tracking it.