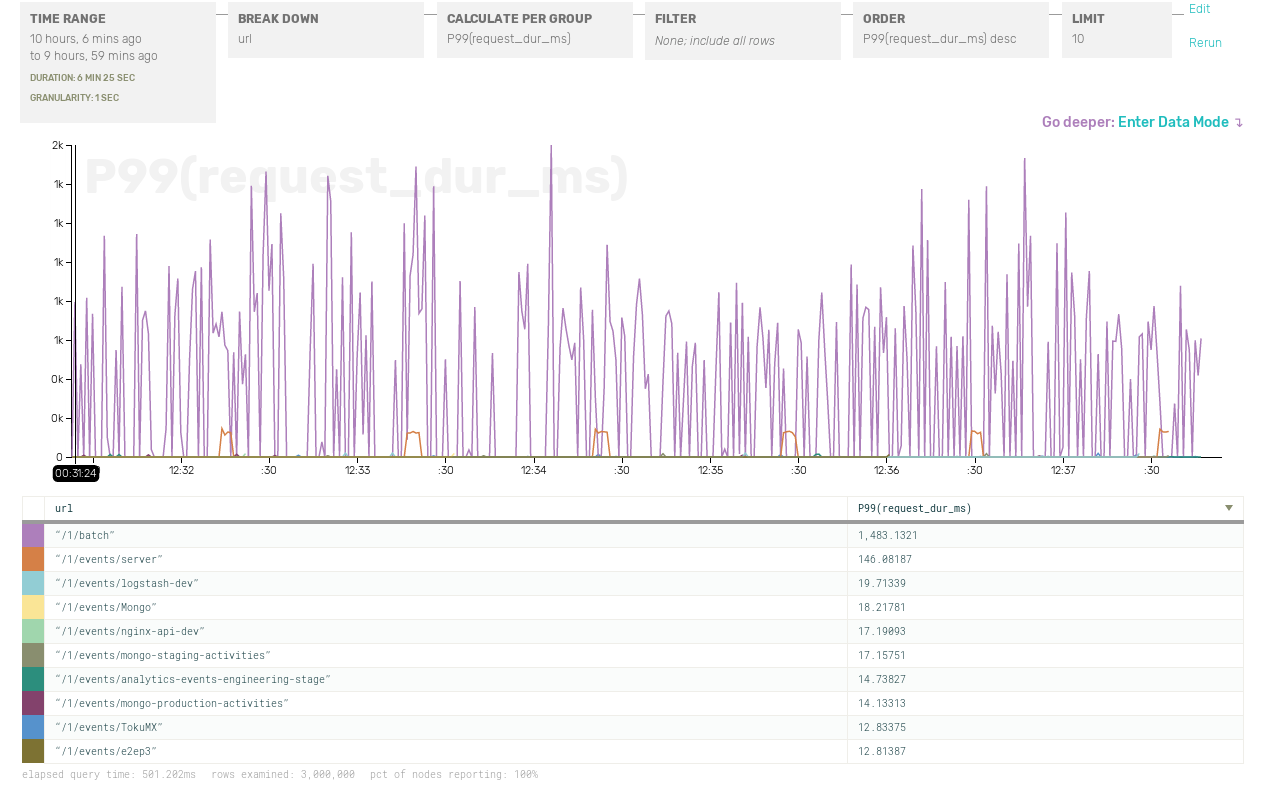
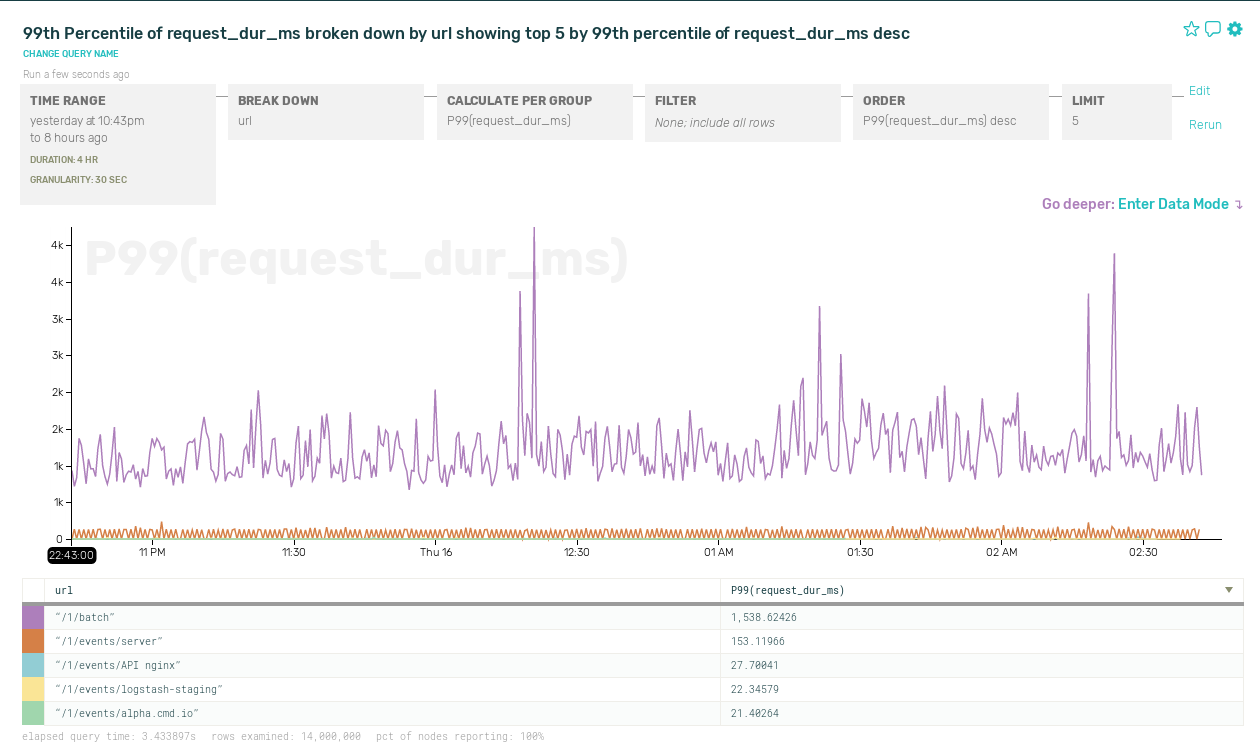
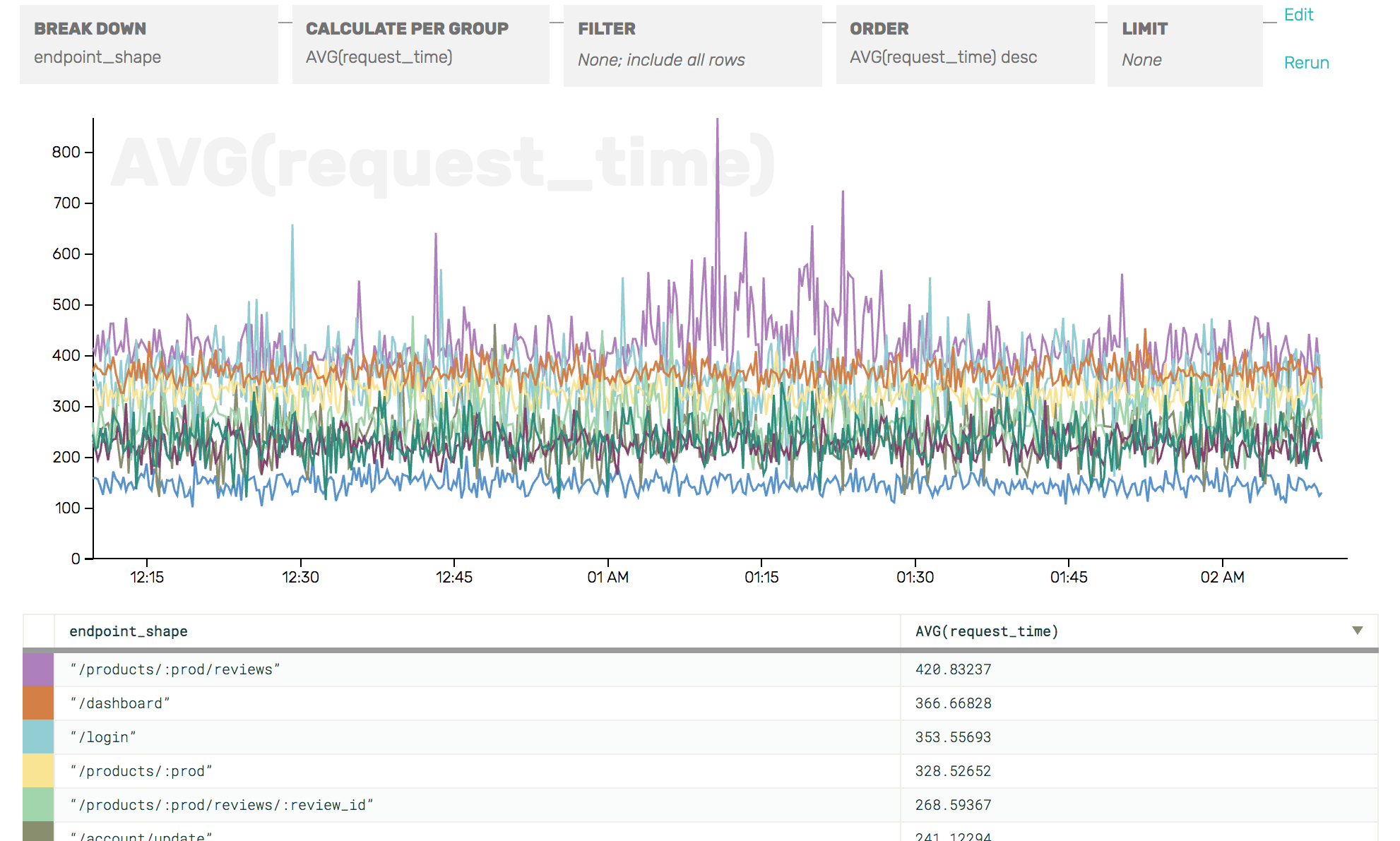
This is the second of three posts focusing on sampling as a part of your toolbox for handling services that generate large amounts of instrumentation data. The first one was an introduction to sampling.
Sampling is a simple concept for capturing useful information about a large quantity of data, but can manifest in many different ways, varying widely in complexity. Here in Part 2, we’ll explore techniques to handle simple variations in your data, introduce the concept of dynamic sampling, and begin addressing some of the harder questions in Part 1.
Constant Sampling
This code should look familiar from Part 1 and is the foundation upon which more advanced techniques will be built:
func handleRequest(w http.ResponseWriter, r *http.Request) {
// do work
if rand.Intn(4) == 0 { // send a randomly-selected 25% of requests
logRequest(r, 4) // make sure to track a sample rate of 4
}
w.WriteHeader(http.StatusOK)
}
Constant sampling is just the idea that you will submit one event for every n events you wish to represent. In the above example, we randomly choose one out of every four events. we call it constant sampling because you’re submitting 25% of all your events—a constant sample rate of 4. Your underlying analytics system can then deal with this kind of sampling very easily: multiply all counts or sums by 4. (Averages and percentiles are unchanged.)
The advantage of this approach is that it is simple and easy to implement. You can easily reduce the load on your analytics system by only sending one event to represent many, whether that be one in every four, hundred, or ten thousand events.
The disadvantage of constant sampling is its lack of flexibility. Once you’ve chosen your sample rate, it is fixed. If your traffic patterns change or your load fluctuates, the sample rate may be too high for some parts of your system (missing out on important, low-frequency events) and too low for others (sending lots of homogenous, extraneous data).
Constant sampling is the best choice when your traffic patterns are homogeneous and constant. If every event provides equal insight into your system, than any event is as good as any other to use as a representative event. The simplicity allows you to easily cut your volume.
Dynamic Sampling
The rest of the sampling methodologies in this series are dynamic. When thinking about a dynamic sample rate, we need to differentiate something we’ve glossed over so far. Here are two ways of talking about sample rate:
- This dataset is sampled four to one
- This specific event represents four similar events
Until now we’ve used the two ways of looking at sampling interchangeably, but each contains a different assumption—the first is only true if all the data in the dataset is sampled at the same rate. When all data is sampled at the same rate, it makes calculations based on the stored data very simple.
The second way of talking about sample rates has a different implication—some other event might represent a different number of similar events. If so, it brings up some severe complications—how do you do math on a body of events that all represent a different portion of the total corpus?
When calculating an average based on events that all have different sample rates, you actually need to walk through each event in order to calculate your average and weight each event accordingly. For example, with three events with sample rates of 2, 5, and 10, to calculate the average, you need to multiply the value in the first event by 2, the value in the second by 5, the value int he third by 10, add up those values, then divide by the total number of events represented (17).
| value | sample rate | contribution to the average |
|---|---|---|
| 205 | 2 | 410 |
| 317 | 5 | 1585 |
| 281 | 10 | 2810 |
| ——- | ————- | —— |
| 17 | 4805 |
Average: 4805 / 17 = 282.65
Within Honeycomb, every event has an associated sample rate and all the calculations we do to visualize your data correctly handle these variable sample rates. This feature lets us start to do some really interesting things with sampling within our own systems: reducing our overall volume while still retaining different levels of fidelity depending on the type of traffic.
Introducing dynamic sampling lets us address some of the harder questions posed in the first post of this series.
Static Map of Sample Rates
Building a static map of traffic type to sample rate is the our first method for doing dynamic sampling. We’re going to enumerate a few different types of traffic and encode different sample rates for each type in our code. By doing so, we can represent that we value different types of traffic differently!
When recording HTTP events, we may care about seeing every server error but need less resolution when looking at successful requests. We can then set the sample rate for successful requests to 100 (storing one in a hundred successful events). We include the sample rate along with each event—100 for successful events and 1 for error events.
func handleRequest(w http.ResponseWriter, r *http.Request) {
// do work
if status == http.StatusBadRequest || status == http.StatusInternalServerError {
logRequest(r, 1) // track every single bad or errored request
} else if rand.Intn(100) == 0 {
logRequest(r, 100) // track 1 out of every 100 successful requests
}
w.WriteHeader(status)
}
By choosing the sample rate based on an aspect of the data that we care about, we’re able to gain more flexible control over both the total volume of data we send to our analytics system and the resolution we get looking into interesting times in our service history.
The advantage of this method of sampling is that you gain flexibility in determining which types of events are more important for you to examine later, while retaining an accurate view into the overall operation of the system. When errors are more important than successes, or newly placed orders are more important than checking on order status, or slow queries are more important than fast queries, or paying customers are more important than those on the free tier, you now have a method to manage the volume of data you send in to your analytics system while still gaining detailed insight into the portions of the traffic you really care about.
The disadvantage of this method of sampling is that if there are too many different types of traffic, enumerating them all to set a specific sample rate for each can be difficult. You must additionally enumerate the details of what makes traffic interesting when creating the map of traffic type to sample rate. While providing more flexibility over a constant rate, if you don’t know ahead of time which types might be important, it can be difficult to create the map. If traffic types change their importance over time, this method can not easily change to accommodate that.
This method is the best choice when your traffic has a few well known characteristics that define a limited set of types, and some types are obviously more interesting for debugging than others. Some common patterns for using a static map of sample rates are HTTP status codes, error status, top tier customer status, and known traffic volume.
For an example of the static map, take a look at the documentation for logstash on our web site and a sample logstash config that includes dynamic sampling based on HTTP status code for logstash.
Up Next - My traffic is a KALEIDOSCOPE of change!
This entry in the series introduced the idea of dynamic sampling. By varying the sample rate based on characteristics of the incoming traffic, you gain tremendous flexibility in how you choose the individual events that will be representative of the entire stream of traffic.
In Part 3 we take the idea of dynamic sampling and apply realtime analysis to dynamically adjust the sample rate! Why stop at a person identifying interesting traffic—let’s let our applications choose how to sample traffic based on realtime analysis of its importance and volume! But until it’s published, try signing up for an account on Honeycomb and sending some data of your own with variable sample rates.