Real-world examples
An interesting side effect of the devopsification of the software industry is how many software engineers and operations engineers increasingly find ourselves in the role of “Accidental DBA,” responsible for operating, debugging, and maintaining a variety of storage solutions at scale.
(Noobs may be interested in Maslow’s Hierarchy of Database Needs, a talk I gave last year on what you should care about and think about as an accidental DBA from the systems or software worlds.)
This can be terrifying at times, but also terrifically fun. :) Databases are complex and opaque and can be challenging to debug. Fortunately, Honeycomb is ideally suited to help people like us bridge that gap, and start confidently navigating the intersections between your software and your storage. (In fact, one inspiration for Honeycomb comes from a piece of software originally designed to help Facebook get some visibility into MySQL! It’s a natural fit.)
Getting data in
Our connector for MongoDB configures an agent to parse and transmit your MongoDB logs. Follow the instructions to turn on full debug logging, set up the connector, and start shipping everything in to Honeycomb.
The connector and agent are both open source and can be set up on any machine with direct access to log files. (Support for hosted MongoDB clusters is coming soon!)
Asking interesting questions
Let’s start with a few basics. As someone with some experience in MongoDB—or any other database—you probably have an idea of what to look for.
There are a bunch of typical database questions and problems that are very useful to be able to answer quickly.
- Display requests per second and look for any patterns or spikes
- Break down all the query types that are getting sent in to my system, and look for read/write ratio
- Get rid of any noisy data in the logs that isn’t related to query traffic
- Look for replication delays, or failing health checks
- Find the slowest queries. Find any collections or databases that are hot spotting
- Am I missing any indexes? (aka, Am I doing any accidental full table scans?)
- Do I have any terrible un-optimized queries that are fucking with my query planner?
- Am I reading or writing too much data per query?
- Do I have any query families dominating lock consumption?
- What are the queries that I am running that are consuming the most resources? How have they changed over time? When was a query family first deployed?
- Trace an outlier query back to a raw result to see where it’s failing
- Show all queries and query families for a given UUID
In this post, though, let’s focus on orienting ourselves with our dataset and using Honeycomb to explore it.
Getting started: isolating by db name, collection and operator type
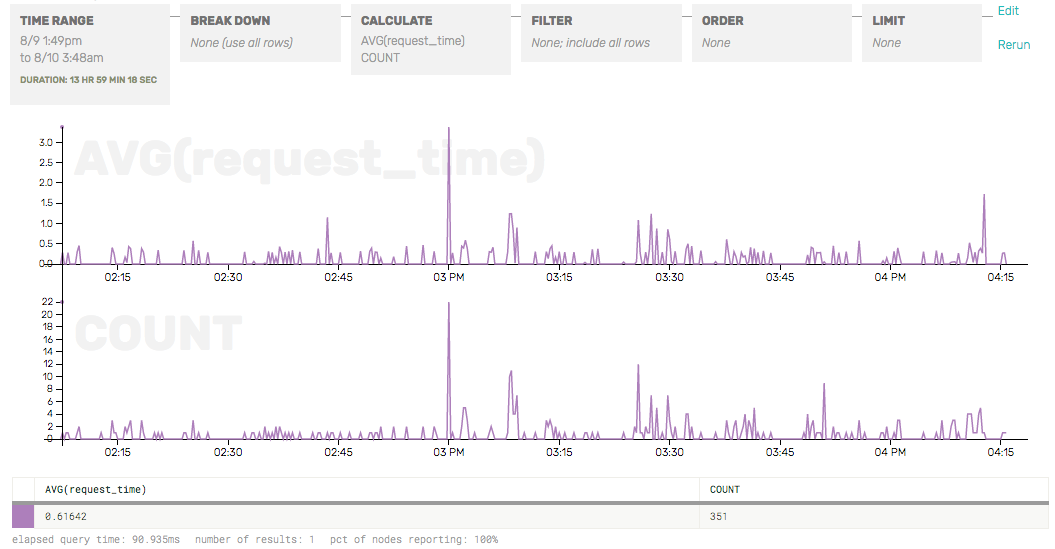
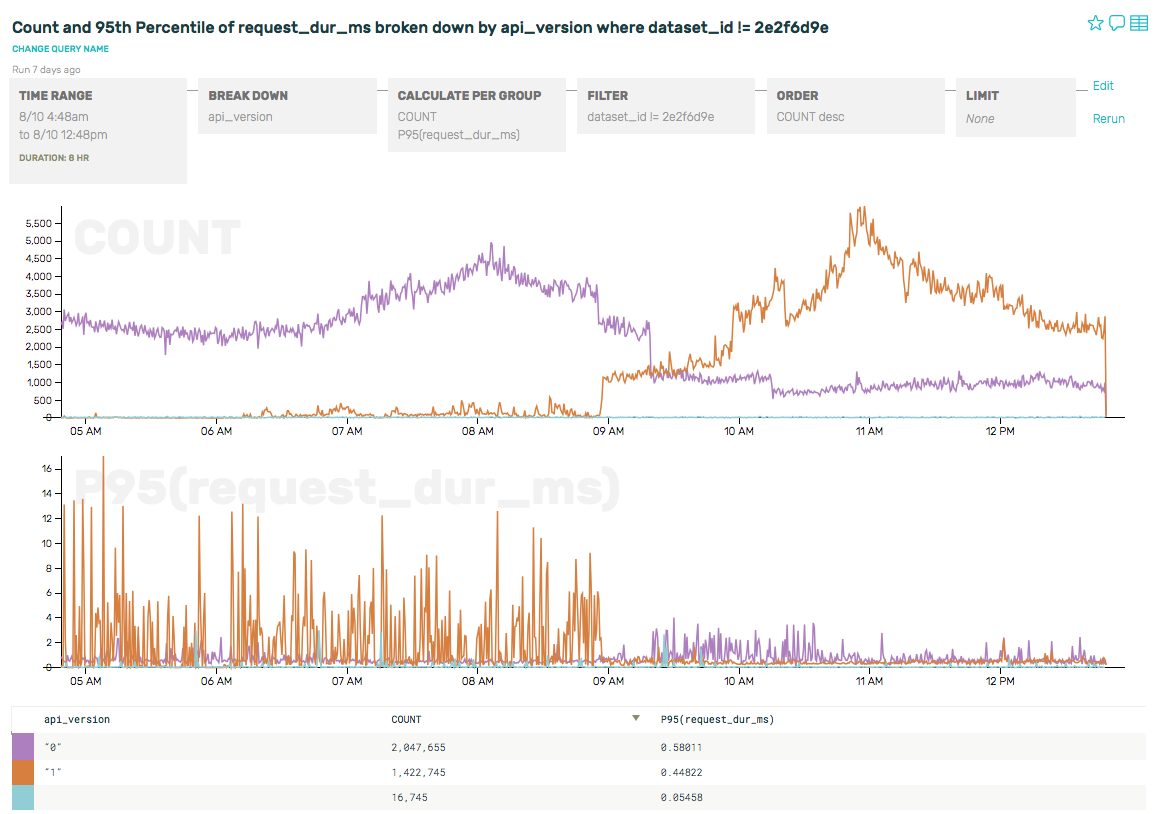
We can start by just getting a count of queries per second, and then break it down further by operator type (insert, update, query, etc) and collection to see what sorts of queries our clients are issuing.
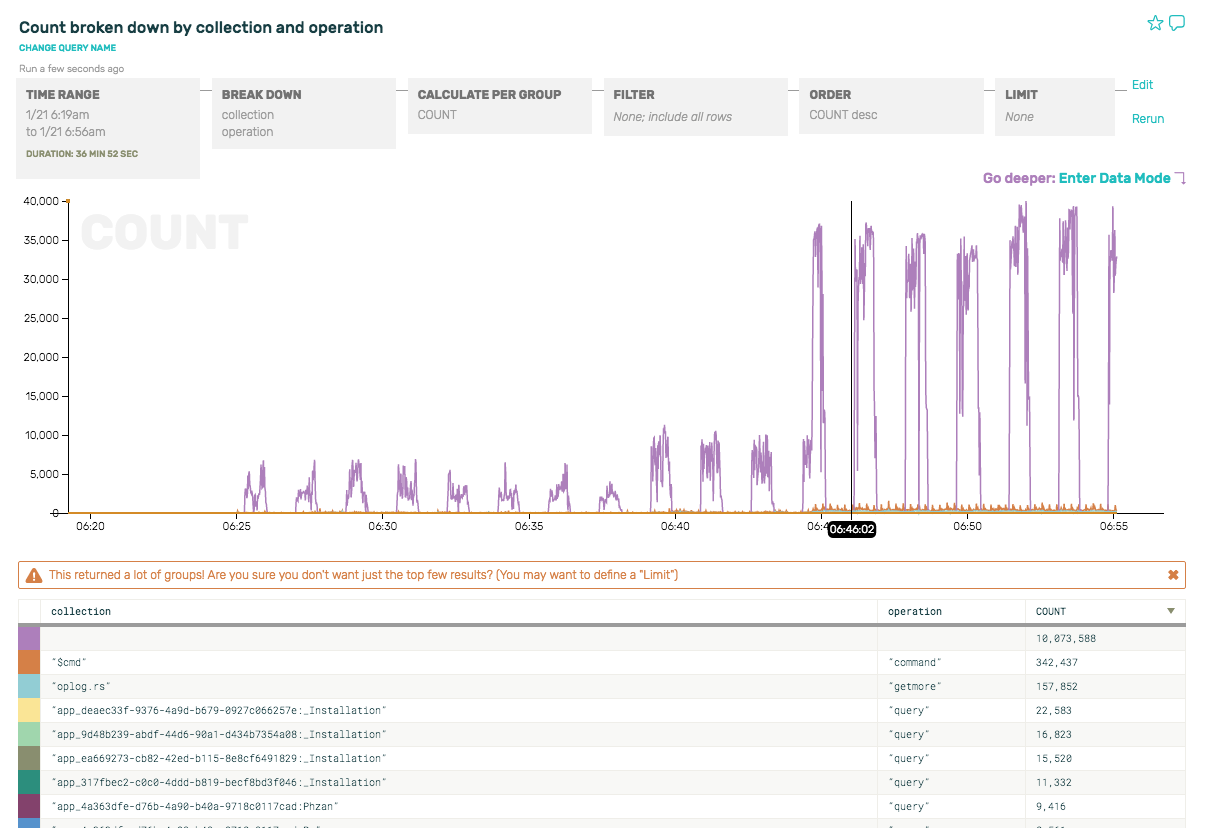
Hmm. There are some periodic spikes that look curious. But the predominant event by far doesn’t even have a query or associated collection at all. What is it?
If we zoom in to one of the minute-long purple spikes there, and peek at the underlying rows, we can see that it’s actually the health checks and other internal commands that mongo executes every other minute. Since we have turned on debug-level mongo logs, all this non-query-related stuff shows up in the logs and is picked up by Honeycomb:
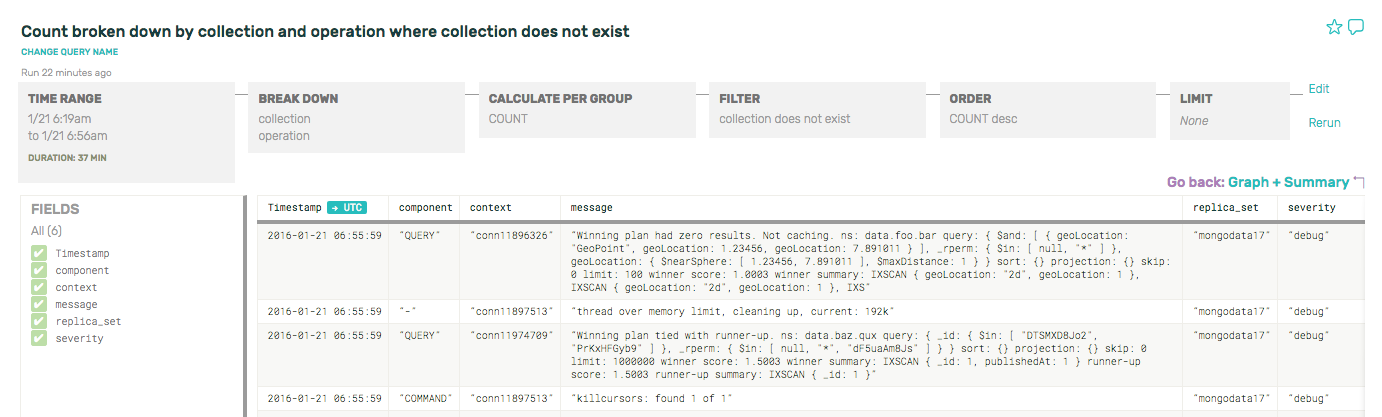
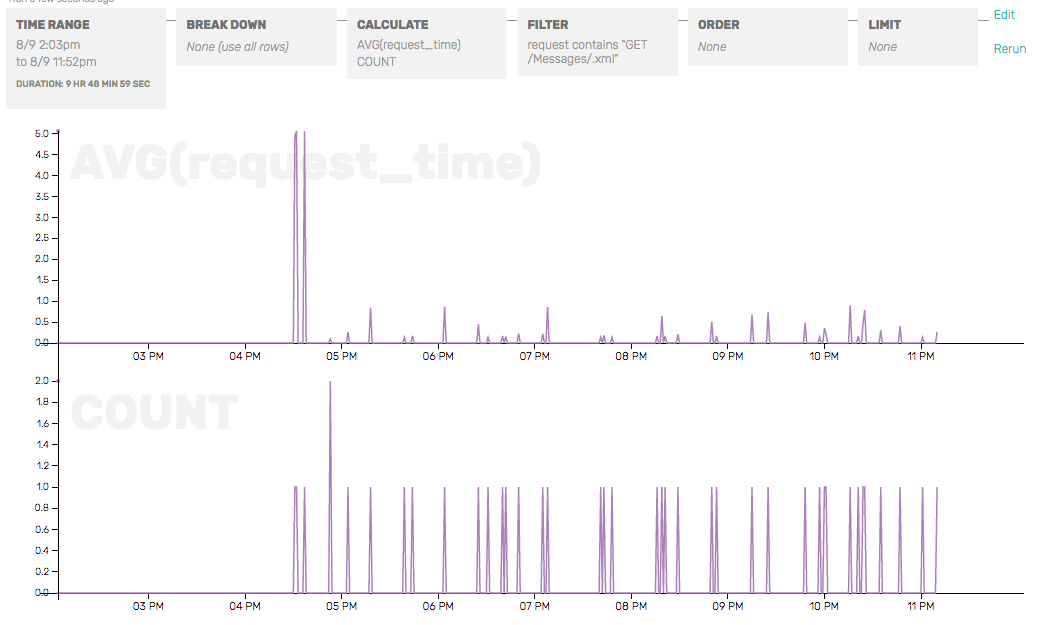
If you’re curious about the mongo internal commands and what they’re doing, for example, break down by command type and see what’s happening under the hood on just the $cmd collection.
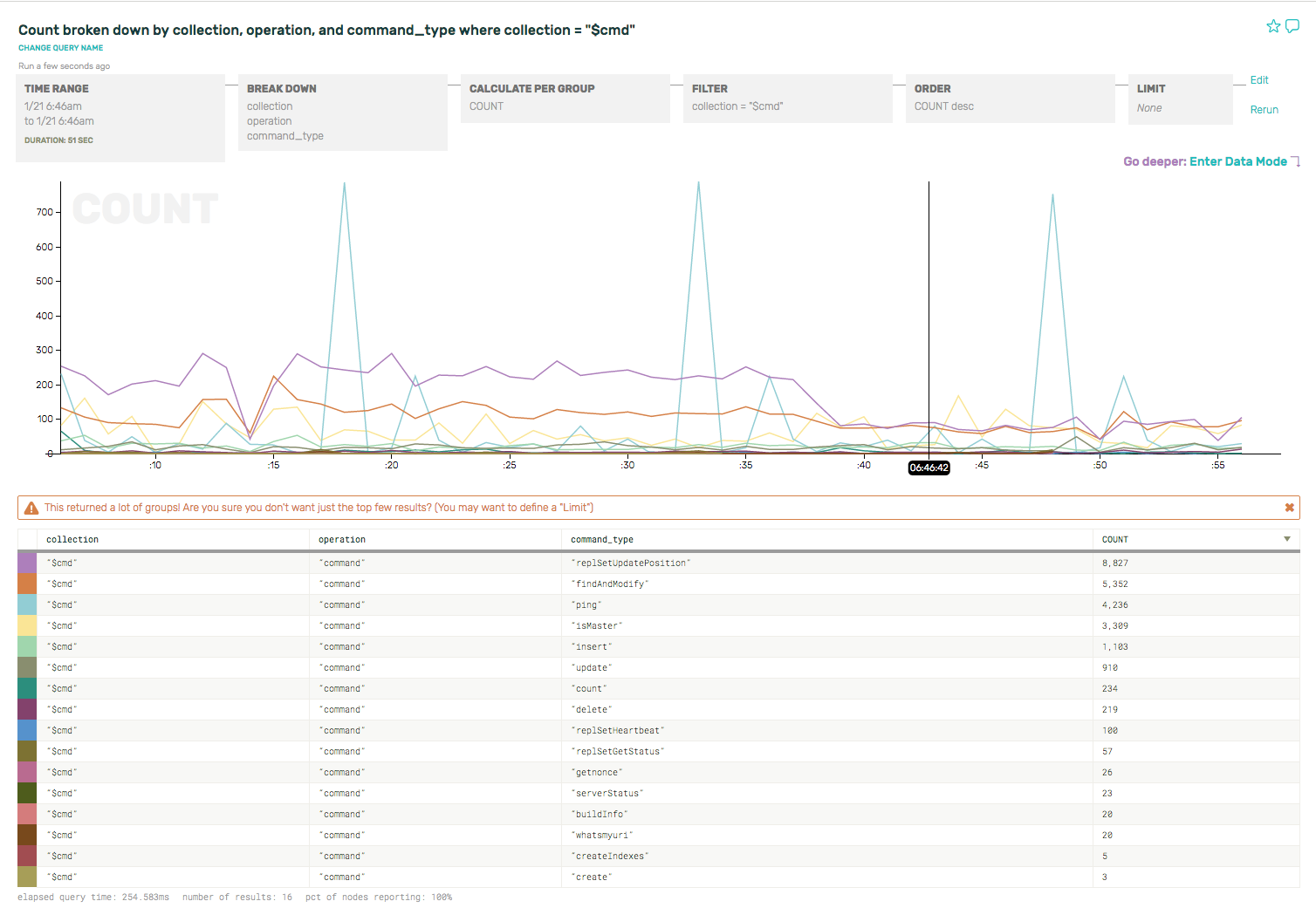
Pretty cool, right? You can see that the replica set heartbeats (command_type == “ping”) and the clients ask whether the node is the master (command_type == “isMaster”) before sending a write. (If not, clients will disconnect and reconnect/re-request replica set state info.)
There’s a few more goodies like this—if you inspect just the oplog.rs collection, you’ll see all the tailable cursors on the oplog collection, doing getmores from IP addresses corresponding to the secondaries’. If you are having problems with replication errors or lag, this is a good place to start looking for those.
Filtering out the noise
But as interesting as all this is, it isn’t super relevant for a DBA trying to get a sense of what’s happening in terms of queries, performance, etc. So to filter out the noise, let’s remove some of the internal commands by adding filters: get rid of severity == “debug”, collection == “$cmd”, collection == “oplog.rs”, in order to limit the results to queries that are coming from our apps and services.
Let’s look at a few basic queries we might run to get a sense of what kind of traffic this replica set is serving.
Now that we’ve stripped out the noisy internal traffic, we can re-run the sort of breakdown we looked at earlier and look at the ratio of query types are for reads vs writes, breaking down by operator type. As you can see, about 93% of the queries are reads, and the rests are writes (insert, update, remove):
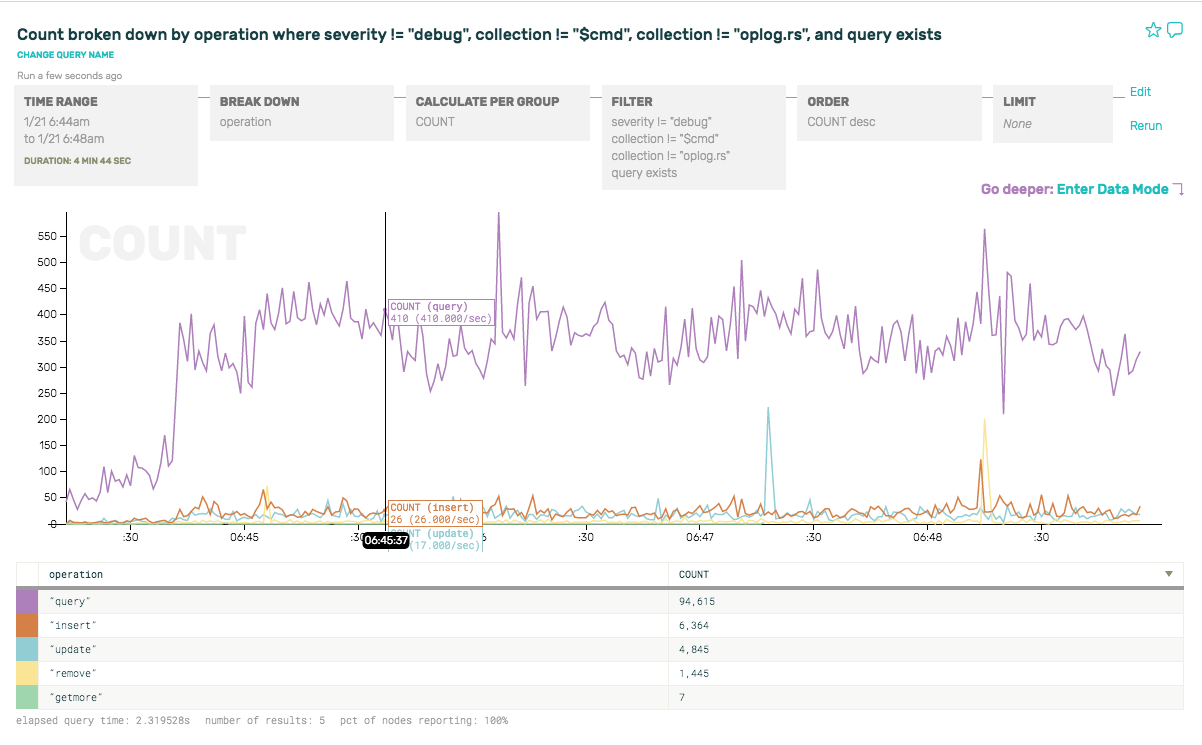
Note that we only have one node here, just the primary node, and that we can only inspect whatever data we get from turning on full query logging for this node. We haven’t yet tossed in the query traffic from secondaries, or enriched it with other important details like pending queue length, system metrics, election events, snapshots or backups, terminated queries, AWS instance type, available RAM, etc etc. We’ll get to that in later posts—we’re only barely getting started!
Let’s add database to the breakdown, in order to find out all the database names, and query count/sec/database. And we’ll do the same with collection to see which collections are hottest.
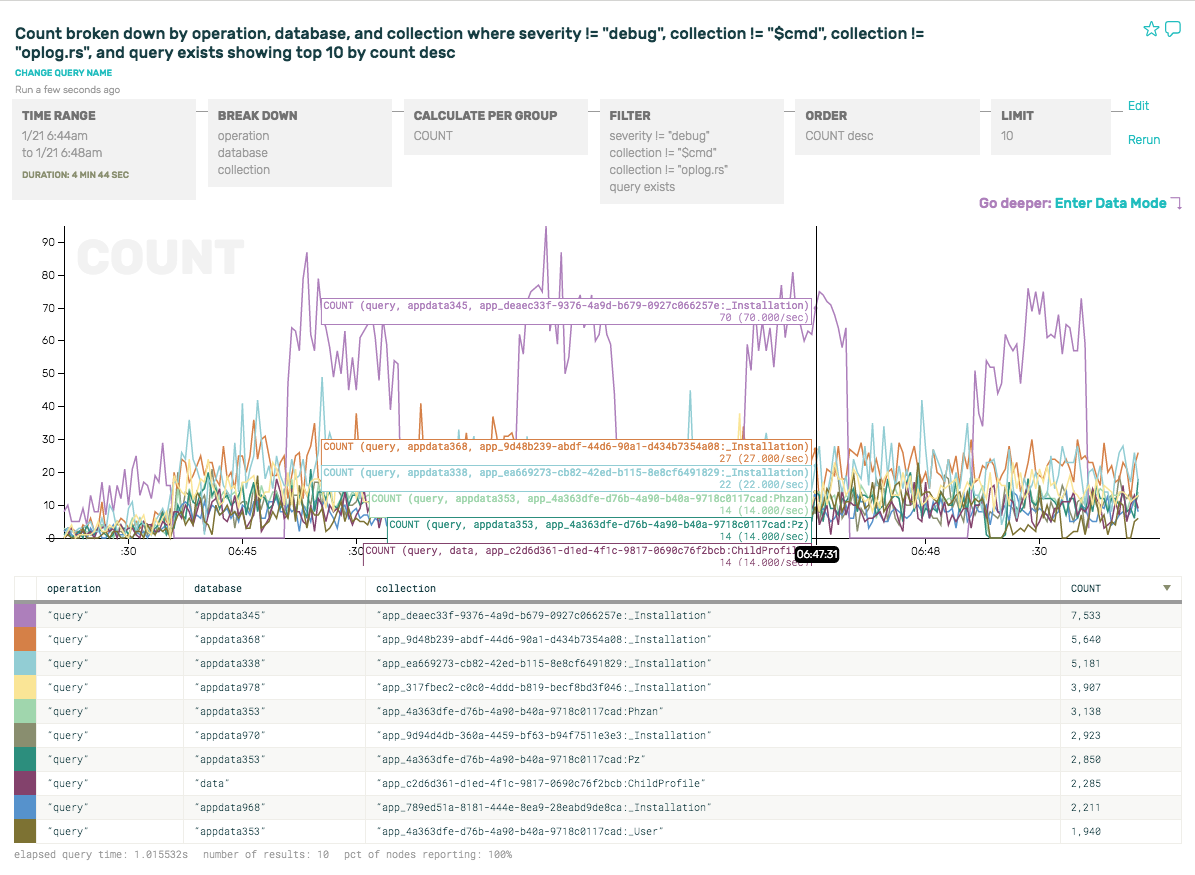
Here you can clearly see that the most common query is on the appdata345 database, where the top query averages out to about 7 req/sec over time—but spikes up to 70 req/sec for intervals every minute (see hover-over numbers for the purple spike):
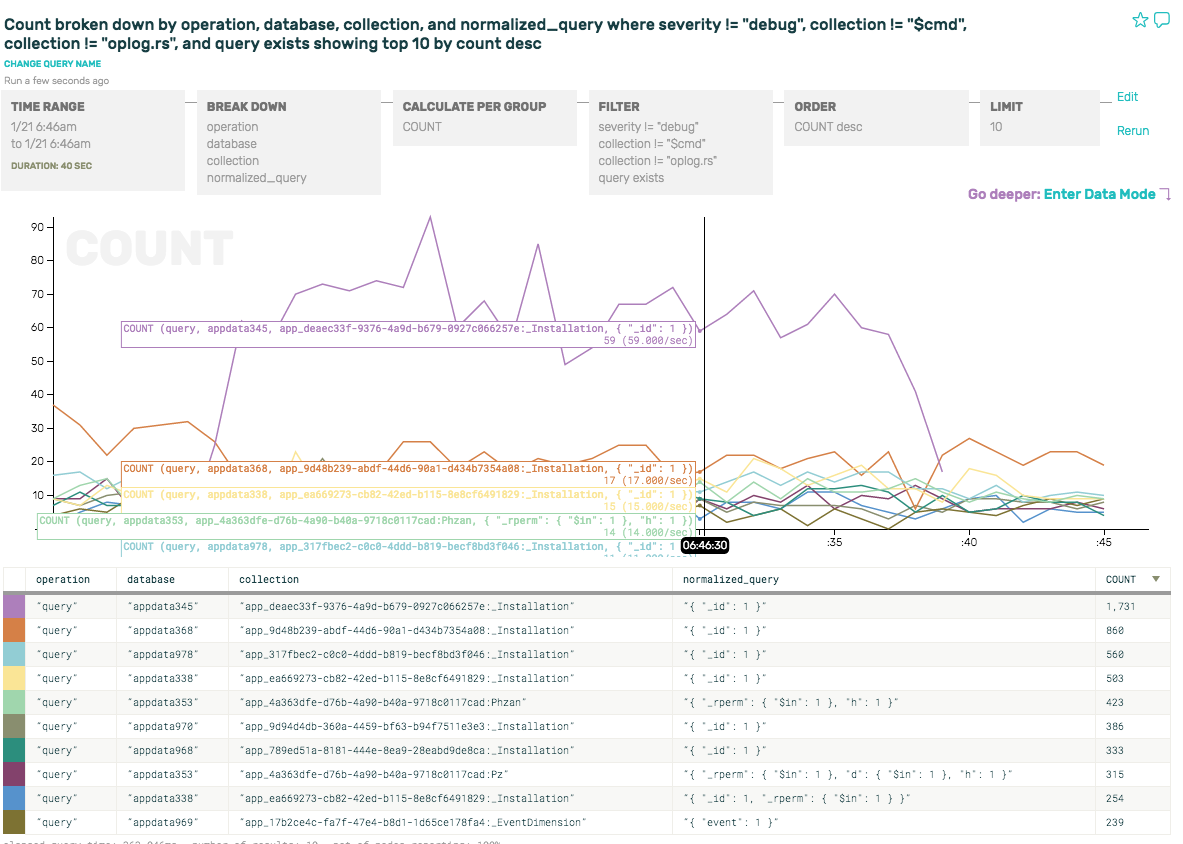
But its most common normalized_query is pretty boring: { "_id": 1 }. Let’s take a look at the appdata353 instead, the 8th row down. Its normalized_query looks a little more interesting. We add a filter to drill down to just that database (database = “appdata353”) and—finally—dig into some actual interesting queries by entering Data Mode.
Below, we can see all the normalized queries, raw queries, connection ids, and a few other fields in the data mode browser. (Note that I’ve deselected most of the fields on the left side, so you can see the most important ones in this view.). If we remove the COUNT from “Calculate Per Group”, we’d automatically pop into this view as there’d be nothing to graph.
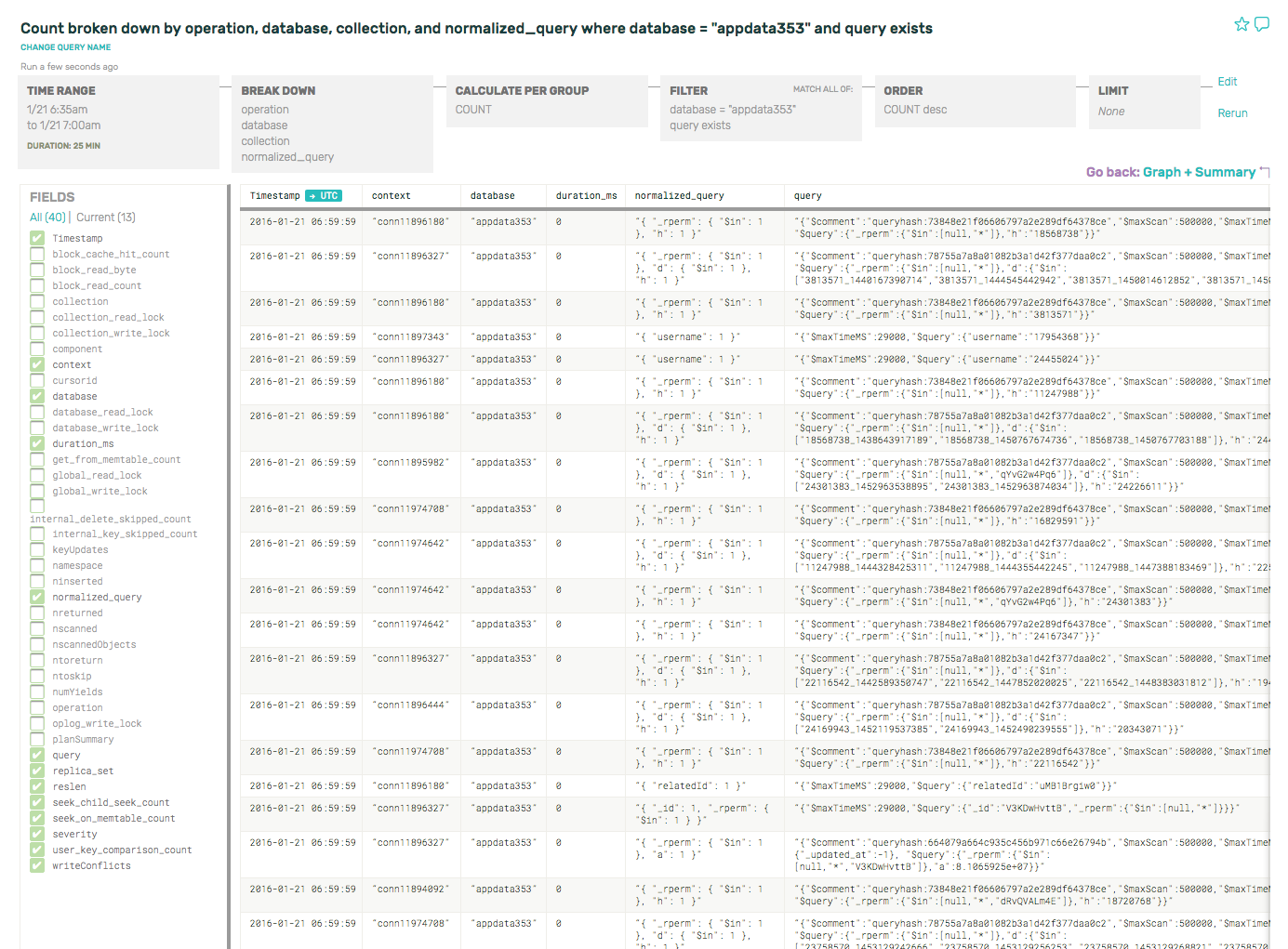
Cool. So now we know how to find basic things like the breakdown of query types, normalized query families, how to dig into a database or collection to debug a QPS spike, search for a string or UUID in a normalized query family, or go deeper into a spike to see what has changed.
Now that we’ve covered the building blocks, we can take a look at more interesting questions. Such as:
- Inspecting metrics like query durations, locks, held, or time waiting for locks—all of which are more meaningful than basic counts
- RocksDB storage engine-specific characteristics (where you could use this data to debug tombstoned documents, memtable statistics, or compaction effects)
- Tricks for tracking down connection origins or tracing unique request ids
Look for how to debug these problems and so much more, coming soon. :)